Why Rust#
Before any specific library, some context on the language. The motivation was not ideological. It was practical and rooted in a specific kind of pain: Fortran code that compiles and runs without complaint, but quietly passes array shapes that do not match what the calling code believes they are. No runtime check, no compiler error, just wrong numbers. That class of silent bug had bitten me enough times that when a new language showed up that made memory safety a first-class guarantee enforced at compile time, it was worth learning seriously. Rust became the language I reached for when exploring new ideas or building tools where correctness under the surface mattered as much as correctness of output. Over time it also became a practical choice for building fast Python libraries through PyO3 bindings, since you get native execution speed with an interface that scientific users can drive from notebooks and scripts without knowing anything about Rust.
The stack that grew from this is not a designed system. Each piece was built when a specific problem came up that nothing else solved well. The order in which they appeared matters to understanding what they are.
mori: Learning Rust Through Orientation Math#
Repository: github.com/rcarson3/mori | Crate: crates.io/crates/mori
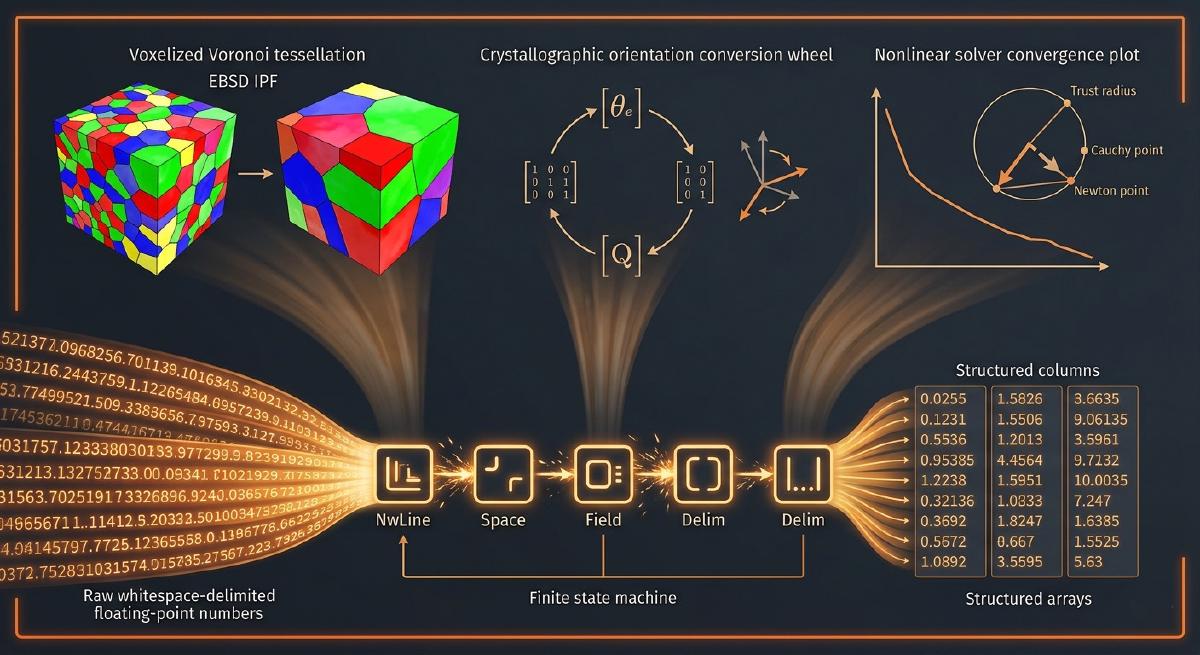
The first project was mori, started in March 2018 while learning Rust. The Rust scientific computing ecosystem was very young at the time: ndarray existed but not much was built on top of it, and implementing something non-trivial with it was itself a useful exercise. The specific problem to solve was crystallographic orientation representations, which made a good choice of subject partly because the math is well-specified and partly because the field had a recurring frustration: different research groups used different conventions for whether a rotation was active or passive, and different parameterizations for the same orientation space, and bugs from these mismatches were subtle enough to survive spot-check tests while corrupting downstream results. Rowenhorst and colleagues had published a paper in 2015 specifically aimed at establishing a common convention, and implementing it carefully in a new language seemed like exactly the kind of project where having the spec nailed down would force the code to be right.
The library covers the full set of orientation representations used in crystallography and engineering mechanics: Bunge Euler angles, rotation matrices, axis-angle pairs, compact axis-angle, Rodrigues vectors, compact Rodrigues vectors, unit quaternions, and homochoric vectors. The central abstraction is an OriConv trait that every representation implements, providing conversions to and from all others. Each orientation type wraps a column-major ndarray::Array2<f64> holding N orientations at once, which is the natural memory layout for FEM data where you process all grains simultaneously. Separate RotVector and RotTensor traits handle passive rotation of 3-vectors and second-order tensors, which are the operations crystal plasticity codes actually need most. The library is split into two crates: mori for the serial implementation and mori-parallel for the version using ndarray’s par_azip! macro to parallelize rotation operations across the collection.
Working through this project properly was a good education in what Rust’s type system actually forces you to think about: ownership of array data, stride assertions for Fortran-order memory layouts (which ndarray doesn’t enforce by default), and how to write clean generic interfaces when the concrete type varies but the operation is the same. The planned future work, mean orientation calculations and misorientation computations following Barton-Dawson and Glez-Driver, would extend the library into the territory where polycrystal texture analysis actually lives.
rust_data_reader: Building a State Machine Parser#
Repository: github.com/rcarson3/rust_data_reader | Crate: crates.io/crates/data_reader
While working on mori in August 2018, the next problem surfaced: there was no Rust equivalent of NumPy’s loadtxt. BurntSushi’s csv crate was fast and well-designed, but it was built around character-delimited formats and could not handle generic whitespace as a delimiter, which is what scientific simulation output files use almost universally. The csv crate came with a detailed blog post from BurntSushi explaining how he had built the parser around a finite state machine, where each parsing state is a distinct type and transitions between states are explicit rather than buried in conditional logic. That architecture is elegant and the blog post is one of the better pieces of technical writing on Rust I have read. So I read it carefully and then built my own parser using the same ideas applied to a different problem.
The parser is organized around a ParserState enum with five concrete state types: NwLine, Delim, Space, Field, and SkField. Each state is a zero-sized struct that implements a Parser trait with methods for each possible byte class it might encounter: delimiter, whitespace, newline, comment, and other (data bytes). The ParserState::next method dispatches on the current state and the next byte, producing a new state. A CoreData struct carries everything the parser needs without allocating: the buffer offset, field counters, column selection information, and a reference to a RawReaderParse trait object that accumulates raw bytes as the parser recognizes fields. Results come back in either row-major (RawReaderResultsRows) or column-major (RawReaderResultsCols) form, and the ReaderResults trait gives you get_row, get_col, and get_value accessors on top of either.
The performance story evolved over time. The initial version was reasonable but not remarkable. Switching to memchr for newline detection made a meaningful difference, since scanning for newlines byte by byte is slower than what a vectorized byte search can do. The biggest jump came from the float parsing backend: the lexical crate (and later fast-float) does u8 slice to float conversion significantly faster than the standard library, and for a parser that spends most of its time turning byte slices into f64 values, that matters a lot. The current implementation reaches around 190 MB/s on a 1 GB float64 file from an SSD. A memory-mapped backend is available behind a feature flag via memmap for cases where the file fits comfortably in virtual address space and you want to avoid buffered I/O overhead entirely. The library also supports arbitrary user types through the load_txt! macro: any type implementing FromStr can be parsed directly, without specializing the reader for that type in advance.
ExaConstit Workflow Crates: Two Problems That Needed Speed#
Both of the Rust crates inside the ExaConstit repository came from the same pattern: a Python script that worked correctly but was too slow at the data volumes the ExaAM project actually produced.
voxel_coarsen: Microstructure Preprocessing#
Repository: github.com/llnl/ExaConstit/tree/exaconstit-dev/workflows
ExaCA, the cellular automata solidification code in the ExaAM pipeline, outputs grain ID fields at fine voxel resolution: every cell in the simulation domain gets an integer grain identifier. Getting from that fine-resolution output to a coarser voxel microstructure that ExaConstit’s mesh generator can work with was originally a Python script, and at the dataset sizes the ExaAM project was producing it was taking long enough to be a practical problem. The voxel_coarsen crate was built to fix that, using rust_data_reader (or optionally polars, both switchable via feature flags) for reading the CSV output files and then doing the coarsening in Rust.
The coarsening logic has two non-obvious steps before the actual mode computation. ExaCA stores its results with y as the fastest-varying axis, then x, then z. ExaConstit’s mesh generator expects x fastest. So the first thing rearrange_data does is reindex the flat grain ID array from ExaCA’s storage order into x-major order while simultaneously grouping each coarse voxel’s worth of fine voxels together in memory. sort_data then sorts each group’s grain IDs, which makes the mode computation in coarsen cheap: a single pass through the sorted chunk is enough to find the most frequent grain ID using run-length counting. Ties, where multiple grain IDs appear equally often, are broken randomly using rand::thread_rng(), with a fixed-size [i32; 32] stack array tracking up to 32 candidates to avoid any heap allocation in the inner loop. The whole thing is exposed to Python via PyO3 under the python feature flag, which made dropping it into the existing Python-based ExaAM workflow straightforward.
xtal_light_up: Diffraction Post-Processing#
Repository: github.com/llnl/ExaConstit/tree/exaconstit-dev/scripts/postprocessing
The second ExaConstit Rust crate came from a different problem. A graduate student had built the original Python scripts for computing simulated lattice strains from ExaConstit output, the process of identifying which simulated grains are oriented to satisfy the Bragg condition for a given crystallographic fiber and then computing the volume-weighted average elastic strain projected along the scattering direction. This work is the computational bridge between simulation and in-situ synchrotron diffraction experiments. The scripts were correct but became slow and memory-hungry as the ensemble sizes grew.
Porting to Rust with PyO3 bindings addressed both problems. The inner loop in strain_lattice2sample is a straightforward iterator chain: take strains and quaternions in chunks of 6 and 4 respectively (Voigt strain notation and quaternion components), apply rotate_strain_to_sample to each pair, write back in place. No temporaries, no Python object overhead per element. calc_lattice_strains is the heavier computation: it takes sample-frame strains, a sample direction vector, element volumes, and a boolean in-fiber mask across all HKL families and time steps, and accumulates volume-weighted lattice strain sums for each fiber at each step. The Rust version keeps memory flat and processes everything in a single pass rather than rebuilding Python arrays between steps. The math module underneath uses the same const-generic style as HelixSnail: dot_prod::<NDIM, F>, norm::<NDIM, F>, outer products, all generic over float type and compatible with no_std. One deliberate limitation: the Rust version supports FCC crystal symmetry only. The more general in-situ C++ implementation in ExaConstit proper later expanded this to all eight Laue groups, but the Rust crate covers the use case it was built for.
HelixSnail: What SNLS Would Have Looked Like#
Repository: github.com/rcarson3/HelixSnail
The most recent addition to the stack and arguably the most technically interesting one. HelixSnail started as a question: if you took everything learned from years of working with LLNL’s C++ SNLS library and were not constrained by SNLS’s original design decisions, what would a small nonlinear solver library look like if you built it in Rust from scratch? The name is a nod to SNLS (Small NonLinear Solver) and the project is also a deliberate vehicle for pushing Rust’s nightly features, particularly const_generics, as far as they will go while keeping the crate no_std compatible in case Rust ever matures to the point of supporting GPU code well enough to run this kind of kernel there.
The library opens with #![no_std], #![feature(generic_const_exprs, generic_arg_infer)], and a FloatType trait that combines num_traits::Float, Zero, One, NumAssignOps, NumOps, Debug, and bytemuck::Pod. That last one is what enables zero-cost reinterpretation between flat [F] slices and structured [[F; NDIM]] array-of-arrays representations via bytemuck::try_cast_slice, which avoids any unsafe code for the layout conversions that small-system solvers constantly need.
The core design decision is that the system dimension NDIM is a compile-time constant, encoded via the NonlinearSystemSize trait with its const NDIM: usize. This is what the generic_const_exprs feature enables: expressions like [(); NP::NDIM]: Sized in where clauses, which let the compiler verify at compile time that the arrays the solver allocates for residuals, Jacobians, and intermediate linear algebra are correctly sized. A user defines their problem by implementing NonlinearNDProblem<F>, which requires only a single method: compute_resid_jacobian(x, fcn_eval, opt_jacobian). The solver owns the solution vector, the delta control state, and all the intermediate workspace, and calls the problem’s residual and Jacobian function at each iteration.
Three solvers are available. TrustRegionDoglegSolver is the workhorse: trust-region method with a dogleg step that blends the steepest-descent Cauchy step and the Newton step based on whether the Newton direction fits inside the current trust radius, reducing to pure Newton-Raphson near the solution. The TrustRegionDeltaControl struct handles trust radius updates with configurable xi parameters drawn from standard trust-region algorithm references, with a reject_resid_increase option for problems where accepting a step that worsens the residual is not useful. HybridTRDglSolver is the Powell hybrid variant: it maintains a QR factorization and applies rank-1 Jacobian updates between full evaluations, the same approach that went into the SNLS hybrid solver when it was needed for difficult Orowan dislocation density model convergence. NewtonBBSolver handles scalar root-finding where analytical bounds are available, alternating bisection and Newton steps depending on which the trust radius permits.
The const_generics story in Rust has required returning to HelixSnail roughly once a year as the feature has evolved. The nightly instability is real and occasionally something that compiled on a previous nightly stops working until the compiler catches up with a new edge case. But the direction of travel has been consistently toward stabilization, and the fundamental idea remains sound: for small dense systems of nonlinear equations where the dimension is known at compile time, encoding that dimension in the type system lets the compiler eliminate all bounds checks and unroll loops in the linear solvers completely. That is exactly the right tradeoff for constitutive model solvers, where you evaluate millions of these small systems and the overhead per system has to be minimal.
The Pattern That Connects Them#
Looking across all five projects, each one started from a real irritation with something that did not exist or did not work fast enough. mori came from orientation convention bugs. rust_data_reader came from a missing library. voxel_coarsen and xtal_light_up came from Python scripts that could not keep up with production data volumes. HelixSnail came from having opinions about what a small solver library should look like after years of working with one that had a different design. None of them were planned as a stack. The fact that they fit together, that voxel_coarsen depends on rust_data_reader, and that HelixSnail embodies lessons learned from C++ SNLS, is a consequence of working in the same problem domain for long enough that the tools you build naturally build on each other.